How a 20ms Middleware Transaction Turned Into 400ms Latency
Even small transactions can become bottlenecks under concurrency. A look at middleware writes, locking, and scalability in Django.
While debugging a frontend issue, we noticed something affecting every Django application across the company: Every request was getting incrementally slower
Following the breadcrumbs
The pattern was consistent. And each refresh added a little more latency with the more requests it had to make.
We started where most people would: the endpoint itself - but nothing.
So what’s the next step?
Simple, profile it. We like to use Django-Silk for RESTful APIs.
Once setup, we were able to view each endpoint individually and that’s when the problem became clear.
On every request, the User.last_login field was being updated and costing ~20 ms to do it.
And this was happening in a 3rd party middleware! Note: This middleware is part of an internal company library, and is used for handling custom authentication flows.
Reading the source code
Let’s look at the bit of code responsible for slowing down (condensed): middleware.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class LoginServiceAuthenticationMiddleware(MiddlewareMixin):
def process_request(self, request):
# ....
local_user, _ = User.objects.update_or_create(
id=self.pk,
defaults={
"username": self.username,
"email": self.email,
"first_name": self.first_name,
"last_name": self.last_name,
"is_staff": self.is_staff,
"is_active": self.is_active,
"is_superuser": self.is_superuser,
"last_login": timezone.now(),
},
)
# ....
It relies on update_or_create.
Looking at Django’s implementation, we find (django/db/models/query.py):
1
2
3
4
5
6
7
8
9
def update_or_create(self, defaults=None, create_defaults=None, **kwargs):
# .....
with transaction.atomic(using=self.db):
# Lock the row so that a concurrent update is blocked until
# update_or_create() has performed its save.
obj, created = self.select_for_update().get_or_create(
create_defaults, **kwargs
)
# .....
Alright, here’s what we need to know about update_or_create. It does two things:
- Create a transaction.
- Once inside, start a
select_for_updatewhich is translated as aSELECT FOR UPDATEstatement.
The issue with SELECT FOR UPDATE, is that when PostgreSQL reads that, it acquires a row level lock.
Now ~20 ms sounds harmless, but when you have concurrent requests, each trying to update user info which requires a lock, you will end up creating a bottleneck. In this case each transaction was lasting ~20 ms, but if you have 20 requests from the same user then that means:
- Each will lock the user row.
- Each will wait
[20 ms * (N-1)]requests ahead of it, so when you are the 20th request in line that means you wait ~380 ms(20 ms * 19)just to start processing.
This process kills concurrency, since now we have to wait sequentially for updates to finish before proceeding.
The Solution
There are several ways to approach this. The simplest: don’t update user state on every request.
The solution that we recommended was to add caching, with a customize-able timeout as to when to update the last_login again. Also, flamegraphs collected with py-spy showed application time spent in this path drop from 34.91% to 4.81%.
Here it is at 34.91%: 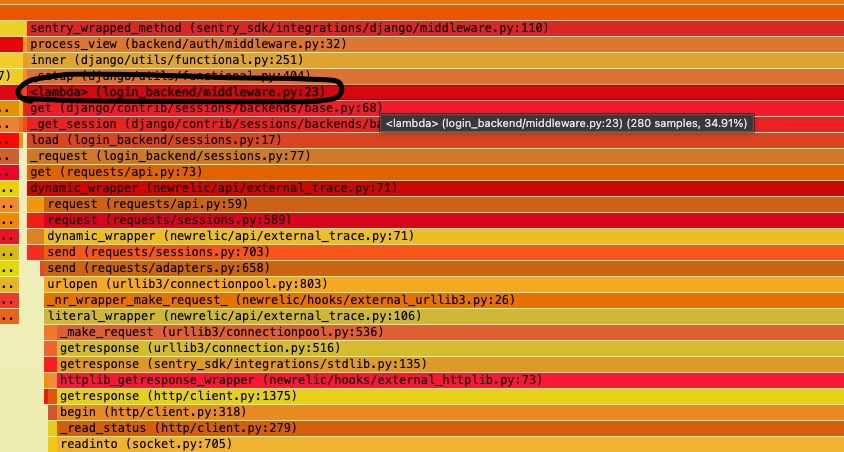
Here are the changes we ended up making in the custom middleware.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# Cache configuration
CACHE_KEY_PREFIX_SESSION = 'login_service_session'
# `0` is the secure default. Effectively disables caching. THIS VALUE CAN NEVER BE None.
# If the value is None then the cache doesn't expire and this whole session backend plugin breaks.
DEFAULT_CACHE_TIMEOUT = 0
# Max timeout is ten seconds. 10 seconds is enough to cut out almost all chatter to the
# login-service while maintain only a 10 seconds lag if permissions change for a user on the
# identity provider or login-service itself.
MAX_CACHE_TIMEOUT = 10
class SessionStore(SessionBase):
def get_cache_key(self, session_key):
return '{}:{}'.format(CACHE_KEY_PREFIX_SESSION, session_key)
def load(self):
if self.session_key:
cache_key = self.get_cache_key(self.session_key)
session_data = cache.get(cache_key)
if session_data is not None:
# Cache hit
return session_data
# Cache miss, request session from login-service
session_data = self._request(requests.get, self.get_endpoint(self.session_key))
if session_data is not None:
if self.session_key:
timeout = get_login_service_cache_timeout()
cache.set(self.get_cache_key(self.session_key), session_data, timeout)
return session_data
self._session_key = None
return {}
The main thing to know is that we are using a custom session backend called SessionStore, and the entry point is load. It’s checking if the cache exists, if not, then it fetches and stores it. Simple but effective.
Here are also some other parts that we update to be complete with this fix:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def save(self, create=False):
#...
timeout = get_login_service_cache_timeout()
cache.set(self.get_cache_key(self._session_key), session_data, timeout)
def exists(self, session_key):
cache_key = self.get_cache_key(session_key)
if cache.get(cache_key) is not None:
return True
session_data = self._request(requests.get, self.get_endpoint(session_key))
if session_data:
timeout = get_login_service_cache_timeout()
cache.set(cache_key, session_data, timeout)
return True
return False
def delete(self, session_key=None):
#...
cache.delete(self.get_cache_key(session_key))
Now with the solution in place, we re-ran sampling and this is our new flamegraph (with sampling at 4.81% instead of 34.91%):
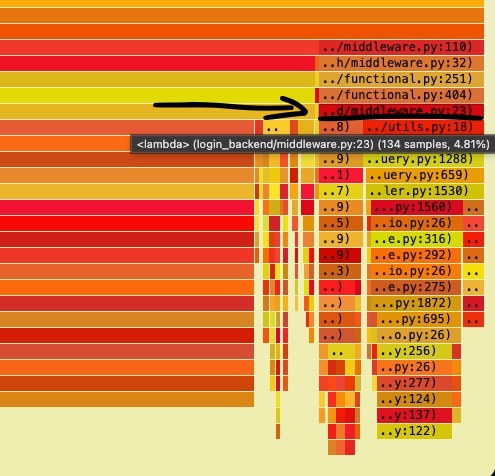
Another solution would be to make the writes asynchronously (via celery) to move the act of updating/locking out of the request/response life cycle. But this brings up an issue such as race conditions (an older task with an old timestamp might overwrite a newer entry), so making tasks idempotent would be needed.
We also investigated whether updating on every request was even necessary but we couldn’t find a requirement that justified it. Still, removing the transaction and row locking from the package wasn’t an option since we didn’t know what other teams depended on that behavior.
With all this being said, this debugging story should serve as another cautionary tale of writing middleware.